Jingfeng Yang
yjfllpyym@gmail.com
yjfllpyym@gmail.com
I started writing this post on Dec 28th, 2023, and finished it on Feb 14th, 2024. All the opinions are my own, not reflecting the view of my affiliation or any others. Actually, this post largely summarizes and elaborates my thoughts expressed on Twitter since March 21st, 2023, as demonstrated in the Appendix. I also added a lot more detailed thoughts from some early Anthropic and OpenAI papers and blog posts. Thanks Hongye Jin and Yijia Shao for providing useful feedback on the initial draft.
Last year saw a boom of LLMs research. Based on the research, one important lesson would be that we should devote most of our efforts to training a general-purpose LLM base model, and leverage it as much as possible after all. I might be opinionated, but I always believe that one general principle is that we need to respect the base model’s capability during alignment. This argument might be common sense among many people, but it is still controversial among others, especially when it comes to the boundary between capability and alignment. Feel free to correct me if you have more solid empirical evidence.
In this post, I will first define model capability and alignment respectively. Then I will discuss capability and alignment boundaries. I will also show some evidence on LLM capabilities coming from the base model and explain why. Based on this, I will introduce some principles to respect base model capability during each method of alignment. Finally, I emphasize the importance of evaluation used to show the effectiveness of our principle.
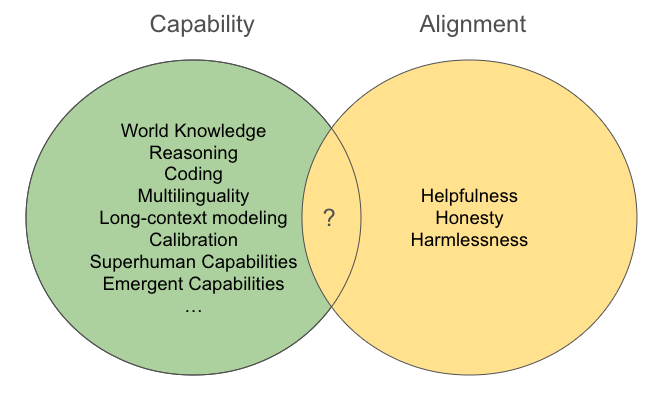
All the arguments are based on the goal that base model construction and alignment is to get a general purpose model, chatbot and A(G)I, or at least a specialist that behaves properly in real-world cases, instead of optimizing performance on any specific tasks and domains or performance on benchmarks.
The alignment problem is defined as “How can we create agents that behave in accordance with the user’s intentions” [25]. In the context of LLM, “agent” could be the language model itself, or the LLM augmented with tools, memories and planning/reasoning abilities as a whole. The “intentions” could be explicit or implicit. Explicit intentions could be requirements expressed in the natural language instructions, while implicit intentions are numerous and hard to be captured by limited objectives or natural language, like “do not be toxic” etc. [26] Those implicit intents could also be ambiguous and diverse, or even inconsistent among different people. Many people currently classify them into three main alignment directions: Helpfulness (Implicit Intent and Explicit Instruction Following), Harmlessness (Safety) and Honesty (Truthfulness and less Hallucinations). In this sense, alignment is more like a goal instead of a method. To achieve the goal of alignment, there could be many methods. The most effective way might be finetuning, including SFT, RLHF and so on. But this goal can be also partially achieved by prompting, or even during the pretraining stage.
Note: specific task alignment is out of the scope of this post, because our goal is to align a generalist model.
There are some common capabilities that are growing when scaling models and corresponding data sizes, like world knowledge, reasoning, coding, multilinguality etc. There are also some other surprising capabilities that are correlated much with scaling of model and data sizes during pretraining. Only given a strong and large enough base model, such capabilities can show up with or without alignment. Given a weak and small base model, even with the same alignment technique, there is still no such capabilities as much. This could indicate that much of them mainly come from the base model instead of the alignment post-training.
In terms of how to pretrain a base model with such strong capabilities, it’s out of the scope of this post. But briefly speaking, what we need to do is to collect a large amount of diverse, deduplicated and high-quality data to pretrain a language model. The main purpose is to ensure the best generalizability of LLMs and avoid collapse. Despite the debate over memorization or generalization, as long as we cover diverse enough domains, and cover enough data, it might not matter whether or not the LLMs are just doing memorization and paraphrasing.
Definitely, improving specific data ratio of pretraining data could improve some specific capability, but it’s still not very clear where the capabilities exactly come from, because pretraining data is too large to do clear control experiments. We should admit that it seems that some capabilities above are improved with post-training, although many of them just improve marginally. So it’s likely that post-training alignment is just to elicit them from the base model.
Then what’s the difference between alignment and capability? We should acknowledge that there are still no clear and well-recognized boundaries between capabilities and alignment. But I will try my best to explain it. Intuitively, alignment is to solve the problem when model has some capability but does not express such capability explicitly (e.g. “the model knows the answer to a question but it does not give out the answer” [26]), because of insufficiency of eliciting model’s capability (e.g. insufficiency of alignment finetuning or insufficiency of clear intents and requirements expressed in the instructions). In practice, it is often hard to test whether the base model has such capability, if the model declines to show such capability. It’s even harder to test and know the limits of a model with superhuman capabilities in some tasks, because human evaluations in those cases are not that reliable and scalable. Also, if we define instruction following capability as explicit intention alignment, probably such capability is mainly developed through finetuning. But if we are talking about fundamental capabilities (e.g. world knowledge, reasoning, coding, multilinguality etc.) required during instruction following, it still comes from the base model. Thus, in the case of instruction following finetuning (SFT or RLHF), finetuning is somehow like mapping explicit human instructions into the base model’s corresponding capability. Without such finetuning, we probably need in-context learning to elicit the corresponding capability from the base model [7].
There has already been much evidence that various capabilities of LLMs mainly come from base models:
Then we might ask the essential reason why capabilities of LLMs majorly come from base models. Capabilities should essentially come from a large amount of data representing that capability, and there should be naturally no bound between pretraining and post-training. But data is scalable during pretraining, while, practically, it’s hard to scale it to the size of pretraining data during post-training and maintaining previous learned capability. We would explain why large amount of data during pretraining might enable various capabilities from three perspectives as follows:
From the AI evolution perspective, LLM might learn such capabilities through language acquisition similarly to humans. Language as the representation is currently the most effective way to learn a generalist AI, because there naturally exists a huge amount of text data on the web. Also, using natural language as representation, LLMs could even learn world models, and learn advanced (super-)human capabilities, assuming those have already been expressed via natural language on the web. Through the language modeling pretraining objective, any capabilities that can fundamentally reduce language modeling loss can potentially emerge [27]. This is also similar to how we humans learn about the world, boost knowledge and other capabilities (e.g. reasoning) through language acquisition. This also sheds light on why one should interact with and leverage the base language model as if we are communicating with and reshaping a human. That’s said, after pretraining, we’d better speak to and align the base model in the natural language space as much as possible so that the base model could understand and digest it better.
From the ML perspective, base model pretraining brings better generalizability. One foundational goal of machine learning is to generalize to unseen distributions, but neural networks are probably not that good at generalization. So the most effective way is to make neural models see nearly the whole distribution during pretraining, so that there is nearly no unseen distributions during usage. The essential reason why LLMs work so well as a generalist is probably that they have seen nearly all the real-world texts during pretraining. Thus the strongest base model could probably already have had the capability to handle all the text related tasks. Therefore, finetuning, as the current most effective way of alignment, is just to elicit base models’ capability to behave in accordance with the user’s intent and complete the user’s task/request, instead of teaching models much new capabilities. Note that it’s still hard to say whether LLM generalizability comes from memorization or generalization. For example, there was one recent debate between approximate retrieval v.s. understanding+reasoning.
From the information theory perspective, base model pretraining might develop intelligence capabilities through lossless compression. During pretraining, when we scale base models, LLMs could have a better language modeling loss (next-token probability) curve which generalizes to the whole texts including those unseen. The lower loss curve we have, the better compression ratio we have, meaning that we have better intelligence. If we truly believe that intelligence comes from such lossless compression, the core capabilities should also be developed during this pretraining process. It’s not possible for finetuning or other similar heavy alignment methods to see such scale of text data and compress them by obtaining a better language modeling probability trajectory over all the texts. Instead, the language modeling loss over pretraining corpus would even slightly increase after alignment finetuning, which might increase the compression ratio and make it a worse compressor, losing some capabilities as general intelligence.
Figure comes from https://www.youtube.com/watch?v=dO4TPJkeaaU
To achieve the alignment goal, our principle is to respect the base model’s capability during alignment. This can be decomposed to three fine-grained principles:
Principle 1: Success of alignment methods highly depends on building the capability of a strong base model, and alignment is just to elicit them in the right direction.
Principle 2: We should maintain the general capability of the base model as much as possible during alignment.
Principle 3: If doing post training to achieve alignment, we should make sure diverse training inputs to maintain the strong general capability of base models.
Principle 1 lays the foundations for why various alignment methods could work and we choose them.
Principle 2 provides one important direction for alignment that is sometimes neglected, which is important for aligning a generalist LLM or a useful AI specialist in the real world. To achieve this, we need to avoid the base model’s collapse, align and then use it in a way that is consistent with the base model. In this sense, the trend from full finetuning to parameter efficient fine-tuning (PEFT, e.g. LoRA, prompt tuning adapters etc.), from discrete prompt optimization to prompt engineering is to gradually change the mindset of adapting LLMs into specific tasks/domains, to fitting any tasks/domains into pretrained language models without overfitting and collapse. Intuitively, changing sparse and less parameters could make base models forget and overfit less, and generalize better, especially for out-of-distribution (OOD) generalization, because those test-time OOD examples are more like in-distribution examples during the pretraining stage. Eventually, prompt engineering is to transform the target task to a natural language prompt, which is in the base model’s input language space and makes the model aware of the task without distorting its parameters or probability space, thus ideally maintaining all the capabilities of base models. Based on this principle, with larger and stronger models, one might expect that alignment procedures after pretraining should be more and more lightweight.
Principle 3 provides high-level guidelines of technical details to maintain the base model’s capability in post-training alignment methods. The “diversity” here encompasses both high coverage and balance. Notice that when the model is getting larger, during finetuning, it’s a common observation that memorization and generalization abilities both get stronger. That’s said, when we work with LLMs, it is easier to memorize and overfit specific patterns and degrade it to a trivial model, given too many similar examples without covering various distributions. Thus, high coverage of difference distribution is important. This is for the purpose that finetuning could support base model capability space without collapse, instead of covering most real-world use cases (e.g. input typos). Because covering most real-world use cases is infeasible when collecting finetuning data, which is why we rely on the base model’s capability to handle most cases. Besides better memorization, a larger model is also easier to handle similar or more generalized samples given just a few examples (more sample-efficient), because it does not need to learn many new things but just need to elicit similar distribution during pretraining. That explains why some limited instances in a narrow distribution could already elicit the base model’s corresponding capability. So we could avoid too many examples in specific distributions and maintain a balance across distributions. In a word, diverse examples during post-training is very important to maintain a base model’s capability in each method.
We use these principles to explain why we choose various alignment methods, and how to avoid pitfalls with each method.
To build a base model’s capability that is more consistent with our alignment goal (Principle 1), one could make the pretraining data more aligned to the target values during base model pretraining, (e.g. filter out harmful or biased contents for the purpose of safety alignment). Besides, a larger and stronger model could potentially have the capability to automatically resolve the conflicted intentions in the pretraining data and align to the spirit of majority data, which represents common human values and alignment goals. One could also expect that the essential instruction following capability increases when the base model is larger and stronger. This makes it possible to use native prompting to lead to a more helpful and harmless model. One could find details in the next section. Meanwhile, the larger model’s self-consciousness, self-consistency, and calibration capability also get stronger, making it more truthful and honest, by outputting meta-knowledge [12], self-consistency checking [13] and calibration [12].
By prompting instead of finetuning, we can maintain the capability of the base model as much as possible (Principle 2). Actually, prompting itself is already a relatively strong alignment method, which has minimal alignment tax compared with finetuning [1]. Alignment with prompting alone could work depending on that we have built a base model with strong capabilities (Principle 1), especially the instruction following and in-context learning capability. In this sense, prompting is just eliciting them. Specifically, proper instruction prompting [1], combined with in-context learning [7], will make the models more helpful, given a large enough model. The larger model would also have the capacity of moral self-correction [11] (i.e. targeted prompts and instructions alone could make the larger model harmless).
When it comes to alignment through finetuning, it is probably the most effective method for alignment till now. Again, maintaining the base model’s capability without degradation of generalizability (Principle 2) during eliciting is crucial to avoid caveats during this process. People could rely on supervised finetuning, best-of-N rejection sampling method, DPO or PPO RLHF to align the model to human values. Sometimes, using strong base models’ capabilities as the successful sauce (Principle 1), Self-rewarding LLMs [28], Constitutional AI [17, 34, 35], scalable oversight [18, 19], weak-to-strong generalization [16], alignment via debate [15] are claimed to be potentially able to align a superhuman base model.
For supervised finetuning, the diversity of instructions and quality of annotated responses are the most important things (Principle 3). This has been mentioned in Self-instruct, LIMA and many other papers [29]. If we imagine that each instruction could elicit one corresponding ability of the base model, and enable the model to follow various instructions of all similar tasks, a set of very diverse instructions could cover most instruction following cases. Note that it is still questionable whether 1000 examples (e.g. in LIMA paper) is enough to lead to a good instruction following model, because more instructions are typically required to cover more rough types of fine-grained capabilities. But if there is too much instruction tuning data (e.g. much more than 52k data used in Alpaca), it’s hard to maintain its balance (one dimension of diversity) and could lead to loss of base model’s general capability and overfitting (againt our Principle 2). Essentially, the reason why Vicuna using ShareGPT data has always been very strong in the lmsys chat arena leaderboard till now, is that the most high-coverage instruction data are those provided by a large group of real-world users (ShareGPT), and it also mostly aligns with human intents. This is consistent with our goal of having a general instruction-following model, instead of optimizing performance on specific tasks. But even for a specific task, leveraging too much task-specific data instead of relying on the base model’s capability is still dangerous. Because there could always be out-of-distribution data for this task, when facing real-world usage. Thus overfitting to limited distribution of this task during finetuning could have a negative impact.
The reason why RLAIF could work is essentially also to leverage strong capabilities of base models to provide preferences (Principle 1), which enable reliable (strong capability) and scalable (automatic model annotation) oversight. Through this, one could still provide human values to be aligned through principles with minimal intervention to the model (e.g. constitutional AI [17]), while avoiding degradation of the base model’s general capability, because we can avoid tuning the reward model with limited and biased human preferences and maintain base model’s capability (Principle 2). Most importantly, we can potentially leverage many superhuman capabilities of the base model (Principle 1) to get a superhuman AGI, especially if we believe evaluation is easier than generation in many tasks [25].
How to align a superhuman AGI through reward modeling? One natural and unified way is to use weak-to-strong generalization to elicit a base model’s capability (Principle 1), although this still poses challenges towards scalable reward modeling [16]. Another is to use scalable oversight methods like recursive reward models [25], which, however, involves more steps and human interventions, potentially hindering base model’s generalizability and scalability (which is slightly against our Principle 2).
DPO seems to have all the advantages of PPO and is more convenient. But we would try to use our principle to compare DPO and PPO, potentially predicting whether DPO will actually be better in the long run.
For DPO, the reward model is implicit, and the generation and reward models are unified, which seems to be more natural and avoid loss of generality, thus more aligned with our Principle 2 to maintain the general base model’s capability. This could be one of the reasons why it could be potentially even better than PPO. But there are also some potential risks compared with PPO. Mixing an RM with the generation policy model could potentially compromise eliciting the evaluator’s better judgment capability (slightly against Principle 1), if it is true that evaluation is easier than generation over some capabilities. There is no explicit reward model so that we can observe, evaluate and control, although we can probably recover the implicit reward model similarly to traditional inverse reinforcement learning (IRL). From the perspective of human behavior, Using DPO (IRL) is similar to “assuming the human is acting to optimize their reward directly, even when this is an inefficient way of communicating their preferences” [18].
Self-rewarding DPO [28] might somehow alleviate such issue by using the generation model as an explicit reward model in each iteration to achieve AI feedback, which not only elicits base model’s judgment capability explicitly (Principle 1) but also leverages the transferability between RM and the generation model (Principle 2). Such transferability is achieved by “translating natural language utterances into the rigid format required for the data set the reward model is trained on, making collecting feedback much more efficient.” [25] That’s said, the model could get more feedback in natural language format, as “natural language is a natural form of feedback for humans” [25]. But there is still another risk no matter whether or not using self-rewarding for DPO: the generation model may update the reward model to make it more easier to hack, making reward hacking more severe [18].
Why do many improper alignment methods that are not following our principle still show good results upon evaluation? That’s because of the imperfection of evaluation data and metric, whose design essentially encompasses the alignment goal.
The obvious common sense is that no single benchmarks are reliable to evaluate a model, especially when we evaluate a model’s general capabilities without overfitting to any tasks or distributions. So if anyone claims finetuning could teach the model some capabilities and significantly increase benchmark scores, that’s obvious but meaningless. First, any benchmarks could just measure performance on a subset in one dimension, which does not reflect general human intents. Second, such finetuning would always sacrifice some general capabilities of models. Importantly, evaluation of alignment definitely requires real-world human feedback (e.g. chatbot arena which has dynamic user inputs and large human feedbacks), because only a wide range of diverse human feedback could reflect diverse human intents in diverse scenarios, which is consistent with our specification of alignment goal. But AlpacaFarm and MT bench, as fixed set evaluation of chatbot instruction following capabilities and multi-turn capabilities, face the same issue as other benchmarks. So do not overrate the performance there. Literally, as Goodhart’s law says, “When a measure becomes a target, it ceases to be a good measure”.
Also, proper evaluation is important to distinguish between capability and alignment by identifying the boundaries of base model capability. Essentially, we need reliable and scalable evaluation methods to explore the limits of model’s capability. When the base model becomes stronger and stronger, it could have superhuman capabilities in some tasks, which means, if we fully elicit the base model’s capability, the tasks it performs will be hard to be evaluated by humans. Obviously it is even harder for people to evaluate where the base model’s capability boundary is before fully eliciting it. In that case, because there is no ground truth, we probably have to rely on a superhuman model itself to do evaluation, optionally equipped with human-AI collaborated evaluation (as demonstrated in sandwiching experimental paradigm) [19]. That’s also the case where we need to build trust with the model, so that we can believe it when using it as an evaluator or supervisor. Interpretability could play a significant role to build trust in such a scenario. As stated in section two, making scalable explanations should probably also rely on a strong and consistent base model itself as a basis, through the model’s natural language expression [14].
Note that any progress in evaluation discussed above could also contribute to model improvement, because “if we had some procedure to evaluate, we could also leverage this evaluation procedure to train the system to be more aligned” [25].
The longstanding bitter lesson [33] says that both scaling and search are important to achieve essential progress of A(G)I. Scaling is definitely the key to base model capability (while data quality and diversity might somehow mitigate the scaling requirements). However, nowadays, search is better to be defined as leveraging the base model’s capability for self-exploration. RL in this case is not to teach, but to elicit and encourage/discourage the base model’s capability. As John Schulman explains “Trust Region Utilitarianism”: “there is a sensible utility function to maximize, but it’s only valid locally around the current state of the world, where the intuitions that produced it are grounded.” A base model with strong capability provides us with such a trust region. And this could probably be a path towards AGI, combining foundations models and self-exploration search. Also the underlying lesson still holds: No matter during pretraining or alignment, let the model itself learn and adapt, and do not force the model to learn in the way how we humans think it should be (e.g. by using too much architectural inductive biases).