Why did all of the public reproduction of GPT-3 fail? In which tasks should we use GPT-3.5/ChatGPT?
The post was written on Feb 12th, 2023. All the opinions in the post are my own.
Why did all of the public reproduction of GPT-3 fail? In which tasks should we use GPT-3.5/ChatGPT?
In this post, I would write down some summaries and my own thoughts on the two questions above, after I carefully checked again with details in a bunch of papers, including GPT-3, PaLM, BLOOM, OPT, FLAN-T5/PaLM, HELM and so on. Feel free to correct me if anyone has more practical experiences or other more reliable references.
The first question is a critical question for those who want to reproduce their own GPT-3/GhatGPT. The second question is important for those who want to use GPT-3/ChatGPT. (When I say GPT-3, it mainly refers to the most recent version of GPT-3.5/Instruct GPT, except for some cases referring to the original GPT3 paper).
Why did all of the public reproduction of GPT-3 fail?
Here I define “fail” as not matching the performance reported in the original GPT-3 paper, with similar or even bigger sizes of models. Under this criteria, GPT-3 and PaLM (540B) are successful, but both of the models are not public, while all of the public models (e.g. OPT-175B, and BLOOM-176B) are “failures”, to some extent. But still, we can learn many lessons from such “failures”. Note that if we have tried different settings for many times, the public community could probably eventually reproduce GPT-3. But till now, the expense is still too high to train even another version of OPT-175B. Because training one pass of such a large model requires running at least for 2 months on ~1000 80G A100 GPUs.
Although some papers like OPT-175B and GLM-130B claimed that they matched or even outperformed original GPT-3 in some tasks, it is still questionable in a wider range of tasks that GPT-3 has been evaluated on. Also, the recent OpenAI GPT3 API results are still much better than such open-sourced models, according to most users’ experience on a wider range of tasks and HELM evaluation. Although the underlying model might use instruction tuning (InstructGPT), the similar instruction-tuned versions of OPT (OPT-IML) and BLOOM (BLOOMZ) are still much worse than InstructGPT and FLAN-PaLM (Instruction-tuned PaLM).
According to paper details, there are multiple probable reasons why OPT-175B and BLOOM-176B failed, compared with the successful GPT-3 and PaLM. I categorize them to two parts: pretrainig data and training strategy.
Pretraining data
Let’s first see how GPT-3 prepares and uses pretraining data. GPT-3 is trained on 300B tokens, 60% of which are from filtered Common Crawl, and other components include webtext2 (the corpus to train GPT2), Books1, Books2, and Wikipidia. Later versions of GPT-3 are also trained on code data (e.g. Github Code). The fraction of each part is not proportional to the original dataset size. Instead, the data with high qualities are sampled more frequently. There are three mysteries which might make the similar data hard to be collected by the open-source community, leading to the “failures” of OPT-175B and BLOOM-176B:
- The first is a well-performed classifier to filter out the low-quality data, which is used to construct the pretraining corpus of both GPT-3 and PaLM. But this step is not conducted by OPT or BLOOM. Some papers have shown that pretraining a model with less high-quality data could outperforms those with much more mixed-quality data. But data diversity is also very important as stated in the third point. Thus, one should be very careful about the tradeoff between data diversity and quality.
- The second is pretraining data deduplication. Deduplication could prevent a pretrained model from seeing the same data point for many times and overfitting/memorizing them, leading to its better generalization. GPT-3 and PaLM conducted document-level deduplication, which is also used by OPT. But there are still many duplications in the Pile corpus used by OPT after this step, as indicated in the OPT paper, which might lead to its inferior performance. (Interestingly, some resent paper indicates that pretraining data deduplication is not as important to avoid overfitting as we previously thought.)
- The third is pretraining data diversity. This includes both domain diversity, form diversity (e.g. text, code, tables) and language diversity. The Pile Corpus used by OPT-175B claimed to have better diversity, but the ROOTS corpus used by BLOOM has too many academic datasets, which lacks diversity of Common Crawl data and probably leads to the inferior performance of BLOOM. In comparison, GPT3 has much more proportion of diverse and general-domain data from Common Crawl, which is probably also one reason why GPT-3 is the first base model leading to a general-purpose well-recognized Chatbot - ChatGPT.
- Note: Although diverse data is generally important for training a general-purpose LLM, specific pretraining data distribution actually affects LLM’s performance on specific downstream tasks a lot. For example, BLOOM and PaLM has more fractions of multilingual data, leading to their better performance in some multilingual tasks and machine translation. OPT has many conversation pretraing data (e.g. reddit), which might lead to its good performance in dialogue. PaLM has a very large portion of social media conversations, which might lead to its superior performance on various Question Answering tasks and datasets. Also, PaLM and later versions of GPT-3 have a large portion of Code data, which increases their ability of coding tasks and probably Chain-of-Thought (CoT) ability. An interesting phenomenon is that BLOOM still shows poor coding and CoT ability despite code data used during its pretraining, which might indicates that coding data alone could not guarantee a model’s coding and CoT ability.
In summary, some papers have shown the importance of the three points above, i.e. deduplication to avoid memorization/overfitting, data filtering for higher quality data, and data diversity to ensure LLM’s generalizability. But, unfortunately, details of how PaLM and GPT-3 preprocessed the data, or the original pretraining data, have not been revealed, which makes the public community difficult to reproduce them.
Training strategy
Here, training strategy encompasses training frameworks, length of training duration, model architecture/training setups, modifications during training procedure, for the purpose of better stability and convergence when training very large models. Generally speaking, loss spikes and divergences have been widely observed in the pretraining process with unclear reasons, thus many modifications to training setups and model architectures have been proposed to alleviate this. But some of them in OPT and BLOOM are not optimal solutions, which might lead to their inferior performance. GPT-3 did not explicitly mention how they solved this issue.
- Training framework: A model larger than 175B typically requires ZeRO-fashion data parallel (distributed optimizer) and model parallel (including tensor parallel, pipeline parallel and sometimes sequence parallel). OPT used FSDP implementation of ZeRO, and Megatron-LM implementation of model parallel. BLOOM used Deepspeed implementation of ZeRO and Megatron-LM implementation of model parallel. PaLM used Pathways, which is a TPU-based model parallel and data parallel system. Details of the GPT-3 training system are still unknown, but they at least used model parallel in some way (some people said it uses Ray). Different training systems and hardwares can actually lead to some different phenomena during training. Obviously, some TPU training setups enclosed in PaLM paper are probably not suitable for GPU training in all the other models. One important implication of hardwares and training frameworks is whether people could use bfloat16 to store model weights, activations, and so on. This has been shown to be a very important factor for stable training, because bfloat16 can represent larger ranges of floating numbers, handling large values during training loss spikes. In TPU, bfloat16 is the default option, which could be one secret why PaLM is successful. But in GPUs, people previously mainly used float16, which is the only option for mixed-precision training in V100. OPT used float16, which could be one factor of its instability. BLOOM identified such an issue and eventually used bfloat16 on A100 GPUs, but it did not realize the importance of such setting, thus applying additional layer normalization after the first embedding, which was used to solve instability in their preliminary experiments of using float16. However, such layer normalization has been shown to cause worse zero-shot generalization, which could be one factor of BLOOM’s failure.
- Modifications during training procedure: OPT did a lot of midflight adjustment and restarted training from a recent checkpoint, including changing clip gradient norm and learning rate, switching to vanilla SGD and then back to Adam, resetting the dynamic loss scalar, switching to a newer version of Megatron. Such midflight adjustments are probably one reason why OPT failed. In comparison, PaLM nearly did not do any midflight adjustment. It just re-started training from a checkpoint roughly 100 steps before the spike started, and skipped roughly 200–500 data batches. Such simple restarting could magically succeed in PaLM, because of its Bitwise determinism where sampling is finished during pretraining data construction, and because of many modifications to the models architecture and training setup for better stability. Such modifications in PaLM are shown in the next point.
- Model Architecture/Training Setup: In order to make training more stable, PaLM made several adjustment to the model architecture and training setup, including using a modified version of Adafactor as the optimizer, scaling pre-softmax output logits, using an auxiliary loss to encourage the softmax normalizer to be close to 0, using different initialization for kernel weights and embeddings, using no bias in dense kernel and lay norms, and using no dropout during pretraing. Note that there are also more valuable lessons in GLM-130B on how to stably train very large models, like using DeepNorm based Post-LN instead of Pre-LN, and Embedding Layer Gradient Shrink. Most of the model modifications are not adopted in OPT and BLOOM, which might cause their instability and failures.
- Training duration: As shown in the following table, the number of tokens seen by the original GPT3 pretraining process is similar to OPT and BLOOM, while PaLM has seen much more tokens during pretraining. Also, PaLM and GPT3 pretraining corpus are both larger than BLOOM and OPT pretraining corpus. Thus, pretraing on more tokens with larger high-quality corpus could be an important factor of GPT3 and PaLM’s success.
| |
Pretraining Corpus Tokens |
Tokens Seen During Pretraining |
| PaLM |
780B |
770B |
| GPT3 |
500B |
300B |
| OPT |
180B |
300B |
| BLOOM |
341B |
366B |
There are some other factors, which are probably not that important for stabler training, but could still affect the final performance. First, both PaLM and GPT-3 used gradually increased (smaller to larger) batch sizes during the training process which has been shown effective to train a better LLM, while OPT and BLOOM used constant batch size. Second, OPT used ReLU activation, while PaLM used SwiGLU activation, and GPT-3/BLOOM used GeLU activation, which typically leads to better performance of training a LLM. Finally, to model longer sequences better, PaLM used RoPE embeddings, and BLOOM used ALiBi embeddings, while original GPT-3 and OPT used learned positional embeddings, which might affect performance with long sequences.
In which tasks should we use GPT-3.5/ChatGPT?
To explain in which tasks/applications we should or should not use GPT-3, I mainly compare prompting GPT-3 with finetuning a smaller model, sometimes with specialized designs, to see whether GPT-3 is suitable for a specific task. This is even more crucial given the good performance of the recent smaller and tunable model FLAN-T5. In the ideal situation, if finetuning GPT-3 is affordable, it might lead to further improvement. However, the limited improvement illustrated by finetuning PaLM-540B on some tasks makes it questionable whether it deserves to finetune GPT-3 in some tasks. From the science perspective, it’s more fair to compare finetuning GPT-3 with prompting GPT3. However, to use GPT3, one might care more about comparing finetuning a smaller model with prompting GPT3. Note that I mainly care about accuracy as metrics, but there are many other important dimensions (e.g. toxicity, fairness etc.) which should be considered when deciding whether to use GPT3, as illustrated in the HELM paper. The rough decision flow is summarized in the following Figure. Hopefully, this can serve as a useful practical guideline, no matter for existing tasks or for a new task.
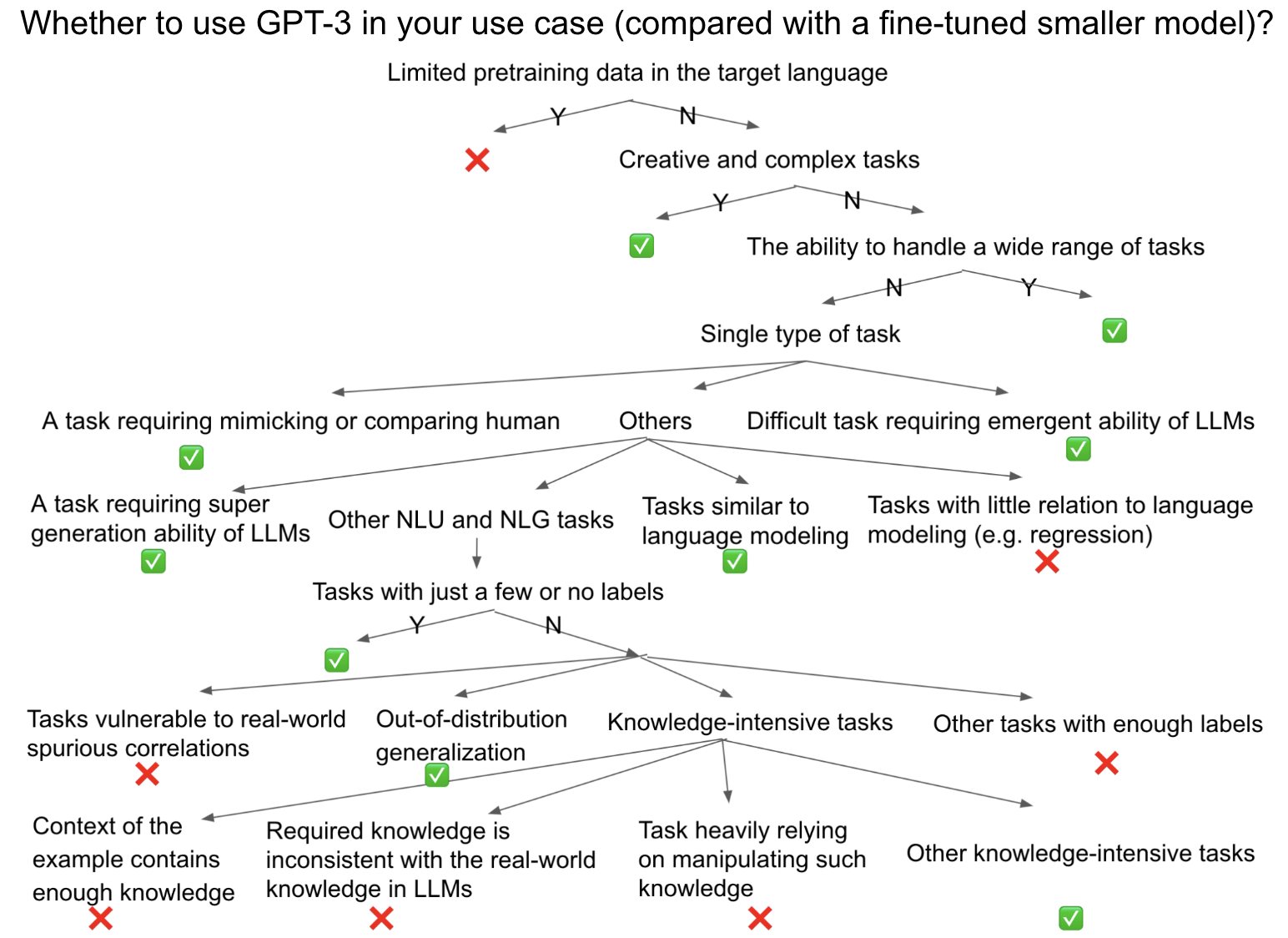
- Note 1: ChatGPT performs well as a chatbot due to its good alignment in the dialogue setting. But we would typically use GPT-3 / InstructGPT (GPT-3.5) / Codex underlying ChatGPT as a general model for more tasks and use cases.
- Note 2: Conclusions in this section are based on some findings of the current versions of the model, which might be not suitable for even stronger models in the future. Because with more pretraining data similar to the target dataset, with academic dataset instruction tuning (e.g. prompting a FLAN-PaLM might give much stronger performance, which has not been public), or RLHF for better alignment to target tasks, the models could be better in target tasks, even sometimes sacrificing some ability in other settings (e.g. alignment tax of InstructGPT). In this case, it is hard to see whether GPT is doing generalization, cross-task generalization, or just have memorized tested data points during pretraining or seen those so-called “unseen” tasks during pretraining. However, whether memorization is actually a severe issue in practice is still questionable, because users, unlike researchers, might not care whether GPT has seen the same or similar data during pretraining, if they find GPT could already perform well on their test data. Anyway, to maximize the practical value of this section in the current world, I tried to compare the best performance of finetuned public smaller models (T5, FALN-T5, some finetuned SOTA with special designs, etc.) and best performance of most-recent GPT-3 (GPT-3.5/InstructGPT)/PaLM (or FLAN-PaLM) if available.
In general, there are several cases where GPT-3 should better be used (it is amazing if we look back at the introduction of GPT3 paper, where many of its initial design goals covers such tasks, which means that those ambiguous goals has been partially achieved):
- Creative and complex tasks, including coding (code completion, natural language instructions to code, code translation, bug fixing), summarization, translation, creative writing (e.g. writing stories, articles, emails, reports, writing improvement etc.) and so on. As the original GPT3 paper illustrated, GPT3 is designed for those tasks which are difficult/“impossible to label”. These tasks, to some extent, were impossible to be used in real-world applications with prior fine-tuned models, while GPT3 makes them possible. For example, recent papers have shown that previous human labeled summarization has been surpassed by LLM generated summarization. And prompting PaLM 540B could even surpass fine-tuned models in some machine translation tasks, which requires translating from low/mid resource languages to English. Similar fashion is also observed in BLOOM-176B. That’s because English data typically accounts for a large portion in pretraining corpus, and thus LLMs are good at generating English sentences. Note that, to get good performance in coding tasks, despite Codex/PaLM’s overall much better performance then previous models, we should still allow LLMs to sample many (k) times to pass the test case (use pass@k as metric).
- Tasks with just a few or no labels. As the original GPT3 illustrated, GPT3 is designed for those tasks which are “expensive for labeling”. In this case, finetuning a smaller model is typically impossible to match GPT3’s zero/one/few-shot performance.
- Out-of-distribution (OOD) generalization. Given some training data, traditional finetuning might overfit to training set and have poor OOD generalizability, while few-shot in-context-learning could have better out-of-distribution generalizability. For example, prompting PaLM could outperform finetuned SOTA on Adversarial Natural Language Inference (ANLI), while it still underperforms finetuned SOTA on normal NLI (RTE dataset). Another example is that prompting LLMs has shown better compositionally OOD generalization than finetuned models. Better OOD generalizability could be either because of no need to update parameters during in-context-learning, avoiding overfitting, or because those previous OOD examples are in-distribution examples for LLMs. This use case is elaborated as one of the initial design goals of GPT3: “The performance of fine-tuned models on specific benchmarks, even when it is nominally at human-level, may exaggerate actual performance on the underlying task, because of spurious correlations in training data, and models’ overfitting to narrow distribution”.
- The ability to handle a wide range of tasks instead of just focusing on superior performance on a specific task. Chatbot is one of such scenarios, where users would expect the bot to respond properly to various kinds of tasks. That’s probably why ChatGPT is one of the most successful use cases of GPT3.
- Knowledge-intensive tasks where retrieval is not feasible. Knowledge stored in a LLM could significantly help improve performance in knowledge-intensive tasks, like Closed-book Question Answering and MMLU (a benchmark dataset including multiple-choice questions from 57 subjects across STEM, the humanities, the social sciences, and more, which tests LLMs’ world knowledge and problem solving ability). However, if a retrieval step could be added (retrieval-augmented generation), a finetuned smaller model (e.g. Atlas Model) could even have better performance (Atlas is better than both PaLM and the most recent InstructGPT in both closed-book NaturalQuestions and TrivialQA datasets). Retrieval/traditional search is also a necessary step when integrating GPT-3/ChatGPT to Search Engine, which could increase generation accuracy, as well as provide more references to increase the convinceness. But we should admit that, in some cases, retrieval is not allowed or not easy, like taking a USMLE (United States Medical Licensing Examination) test, where Google has shown that a FLAN-PaLM based method could do very well. Also, in MMLU benchmark, PaLM-540B has better performance than any finetuned models, even combining retrieval, despite that the most recent version of InstructGPT is still worse than finetuned SOTA with a retrieval step. Note that instruction-tuning a smaller model can also achieve similar effect to scaling to LLMs, which has been shown by FLAN-T5.
- Some difficult tasks which require emergent abilities of LLMs, like reasoning with CoT and complex tasks in BIG-Bench (including logical reasoning, translation, question answering, mathematics tasks). For example, PaLM has shown that, among 7 multi-step reasoning tasks, including arithmetic and commonsense reasoning, 8-shot CoT is better than finetuned SOTA on 4 tasks, and could nearly match fintuned-SOTA in remaining 3 tasks. Such success comes from both scaling and CoT. PaLM also shows discontinuous improvements for BIG-Bench tasks from 8B to 62B to 540B models, which exceeds the scaling law and is called emergent ability of LLMs. 5-shot prompted PaLM-540B outperforms prior (few-shot) SOTA on 44 out of the 58 common tasks in Big-Bench. PaLM-540B also outperforms the average human performance on aggregate.
- Some scenarios which require mimicking humans, or whose goal is to make an AGI with human-level performance. Again, Chatbot is one of such cases, where ChatGPT makes itself more like a human, leading to its phenomenal success. This is elaborated as one of the initial design goals of GPT3: “Humans do not require large supervised datasets to learn most language tasks. Humans could seamlessly mix together or switch between many tasks and skills through at most a few examples. Thus traditional finetuning methods lead to an unfair comparison with humans, despite their claimed human-level performance in many benchmark datasets.”
- Few-shot PaLM 540B could roughly match or even surpass finetuned SOTA on some traditional NLP tasks similar to language modeling, like Ending Sentence/Word Cloze, and anaphora resolution. But, zero-shot LLM is enough in such cases, while one/few-shot examples are typically of less help.
There are also several cases where there is no need to prompt GPT-3-size model:
- Calling OpenAI GPT3 API is out of the budget (e.g. for new startups without much money).
- Calling OpenAI GPT3 API could raise some security issues (e.g. data leakage to OpenAI, or potentially generated harmful contents).
- No enough engineering or hardware resources to host a similar-size model, as well as eliminate the inference latency issue. For example, without the most advanced 80G A100 or engineering resource to optimize inference speed, using Alpa naively to host A100 on 16 40G A100 GPUs requires 10 seconds to finish one-instance inference, which is an unacceptable latency for most real-world online applications.
- If we want to replace a well-performed finetuned module with high accuracy with GPT3, or want to develop a NLU/NLG model in some specific tasks and use cases, we need to think twice whether it deserves.
- For some Traditional Natural Language Understanding (NLU) tasks, like classification, I recommend to finetuning FLAN-T5-11B first, instead of prompting GPT3. For example, In SuperGLUE, a difficult NLU benchmark, including reading comprehension, textual entailment, word sense disambiguation, coreference resolution, and causal reasoning tasks, all of the PaLM (540B)’s few-shot prompting results are still worse than a finetuned T5-11B, with significant gaps in most tasks. With the original GPT3, the gap between its prompting results and finetuned SOTAs’ results are even larger. Interestingly, even finetuned PaLM only leads to limited improvements over fintuned T5-11B, and finetuned PaLM is even worse than a finetuned encoder-decoder 32B MoE model. This shows that finetuning smaller models with more suitable architectures (e.g. encoder-decoder) is still a better solution than using very large decoder-only models, no matter finetuning it or prompting it. For even a most traditional NLU classification task - sentiment analysis, ChatGPT is still worse than finetuned smaller models according to a recent paper.
- Some difficult tasks which are not grounded to real-world data. For example, there are still many difficult tasks in BigBench for LLMs. Specifically, the average human performance is still higher than PaLM 540B on 35% of BigBench tasks, and there are some tasks where scaling even does not help, like navigate and mathematical induction. In mathematical induction, PaLM makes many errors when assumption in the prompt is incorrect (e.g. “2 is an odd integer”). Similar trend is also observed in the inverse scaling law challenges, like redefine-math (e.g. a prompt might “Redefine π as 462”). In such cases, the real-world prior in LLM is too strong to be overridden by prompts, while finetuning a smaller model could probably better adapt to counterfactual knowledge.
- Using few-shot prompting GPT is still worse than fintuned smaller models in many multilingual tasks and machine translation (MT) tasks, which is most likely because of less portion of pretraining data in languages other than English.
- PaLM and ChatGPT is still worse than MT-finetuned smaller models when translating from English to other languages, and translating high-resource languages to English
- There is still a large gap between few-shot PaLM 540B and fine-tuned smaller models for multilingual Question Answering
- For multilingual text generation (including summarization and data-to-text generation), there is still a large gap between few-shot PaLM 540B and fine-tuned smaller models. Even finetuning PaLM-540B only leads to limited improvements over fintuned T5-11B in most tasks, and is worse than fine-tuned SOTA.
- For commonsense reasoning tasks, there is still a large gap between the best few-shot prompting LLMs and finetuned SOTA, like OpenbookQA, ARC (both Easy and Challenge version), and CommonsenseQA (even prompting with CoT), compared with much better performance mathematical reasoning.
- For machine reading comprehension tasks, there is still a large gap between the best few-shot prompting LLMs and finetuned SOTA. In most datasets, the gaps are extremely large. That’s probably because all the knowledge required to answer a question is already available in the given passage, and do not require extra knowledge in LLMs.
To summarize, the above tasks fall in to one of the following categories:
- Some NLU tasks which neither require knowledge nor require generation abilities of LLMs, which means that test data points are mostly in the same distribution as training data points in hand. Such tasks are already performed well enough by previous finetuned models.
- Some tasks that do not require much extra knowledge from LLMs, because each example already contains enough knowledge in its contexts/prompts, like machine reading comprehension.
- Some tasks which require extra knowledge, but are unlikely to get enough knowledge, or see similar distribution from LLMs, like tasks in some low-resource language where LLMs have limited pretraining data in such language.
- Some tasks that require knowledge, which is inconsistent with the knowledge in LLMs or not grounded to most real-world language data. Because LLMs are trained on real-world language data, it is hard to override the knowledge with counterfactual knowledge in new tasks. Besides the “redefine-math” problem in inverse scaling law challenge, there is another example called “modified quote repetition”, where LLMs is asked to repeat a modified famous quote in the prompt. In this case, LLMs is inclined to repeat the original famous quote, instead of the modified version.
- Some tasks that require knowledge from LMs, but also heavily rely on manipulating such knowledge, where such manipulation could not be easily solved by the LLM next-token prediction objective. One example is some commonsense reasoning tasks. The reason why CoT and least-to-most prompting could help LLM reasoning is probably they can better call out those continuous pretraining texts, which happens to mimic the process of planning and decomposing/composing knowledge. Thus CoT and least-to-most prompting perform well in some mathematical reasoning, coding and other simple natural language reasoning tasks, but still struggles in many commonsense reasoning (e.g. deductive reasoning as explained in inverse scaling law) and wired symbolic reasoning tasks, which are not encompassed by most real-world continuous sequences in natural language data, and require manipulating distributed knowledge.
- Some tasks which are vulnerable to spurious correlations in in-context-learning examples or real-world data. One example is Negation Question Answering from the Inverse Scaling Law challenge. If a LLM is asked “If a cat has a body temp that is below average, it isn’t in”, it is inclined to generate “danger” instead of “safe ranges”. That’s because the LLMs is dominated by the relation between “body temp that is below average” and “danger”, which, instead, is a spurious correlation with a negation.
- Some tasks where the objective is largely different from language data, like regression problems, where finetuned models are difficult to be replaced by LLMs. As for multimodality tasks, they could not be finished by LLMs, but could potentially benefit from better large pretrained multimodality models.
- Some tasks which do not require emergent abilities of LLMs, to categorize more such tasks accurately, we need to better understand where such emergent abilities come from during LLM training.
Note that, in real-world use cases, even without the ability to use LLMs online to meet the latency requirement, one can still use LLMs to generate/label data offline. Such labeled data could be looked up and provided to users online, or be used to finetune a smaller model. Using such data to finetune a smaller model could alleviate the human-annotated data required to train a model, and inject some emergent abilities (e.g. CoT) of LLMs to smaller models.
In conclusion, when there is enough labeled data, considering the amazing performance of open-resource FLAN-T5 in many tasks, I recommend one with limited resources of calling OpenAI API to first try to finetune a FLAN-T5-11B on the target task. Also, according to recent amazingly better performance of FLAN-PaLM 540B compared with the most recent version of InstructGPT’s performance on MMLU dataset (according to HELM), Google is likely to have the even stronger base model than OpenAI, if OpenAI has already vendored their strongest LLM through the API. The only remaining step for Google is to align this LLM to the dialogue scenario through human feedback. I would not be surprised if they have a similar or even better chatbot like ChatGPT soon, despite their recent “unsuccessful” release of Bard, which is probably based on LaMDA.
References:
- HELM: Holistic Evaluation of Language Models and its board: https://crfm.stanford.edu/helm/v0.2.0/?group=core_scenarios
- GPT3: Language Models are Few-Shot Learners
- PaLM: Scaling Language Modeling with Pathways
- OPT: Open Pre-trained Transformer Language Models
- BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
- FLAN-T5/PaLM: Scaling Instruction-Finetuned Language Models
- The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
- InstructGPT: Training language models to follow instructions with human feedback
- Yao Fu’s blog on “Tracing Emergent Abilities of Language Models to their Sources”
- Inverse Scaling Prize: https://github.com/inverse-scaling/prize
- Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
